Blog
Release of upscaledb 2.2.1
Posted on Jul 02, 19:33:12 CET 2017 - SHARE:
This release has a few new (minor) features and a couple of bug
fixes. The most important change is not in code, but in the license. With this
release, I will no longer offer paid licenses. Instead, the code is released
under the Apache Public License 2.0, and free for use in closed, commercial
applications.
I have never worked full-time on upscaledb (and its predecessor hamsterdb), but the amount of time I have invested was often more than 40 hours per week. Over
the last year I realized that I do no longer have the resources and the grit to
do this. Spending time with the family is just way more valuable.
Still, it was a difficult decision. For many years I had the vision to write
database code for a living. Working on my own database, my own project, felt
like a dream coming true. Commercially, the dream turned out to be not
sustainable. It did not feel good to see that others had the same problems, but it helped nevertheless.
What now? I will continue working on upscaledb. I will invest my limited time
where it makes most sense (for me). Things that I do not enjoy or that consume
too much time will be neglected. That's mostly related to providing Win32
builds (if you look at the download page then you will see that they are
missing). Bugs will be fixed as soon as possible, patches are more than
welcome.
From the release notes:
New Features
- Added a new API function for bulk operations (ups_db_bulk_operations in ups/upscaledb_int.h)
Bugfixes
- Fixed compiler error related to inline assembly on gcc 4.8.x
- Fixed bug when ups_cursor_overwrite would overwrite a transactional record instead of the (correct) btree record
- Fixed several bugs in the duplicate key consolidation
- issue #80: fixed streamvbyte compilation for c++11
- issue #79: fixed crc32 failure when reusing deleted blobs spanning multiple pages
- Fixed a bug when recovering duplicates that were inserted with one of the UPS_DUPLICATE_INSERT_* flags
- Minor improvements for the journalling performance
- Fixed compilation issues w/ gcc 6.2.1 (Thanks, Roel Brook)
Other Changes
- License is now Apache License 2.0
- Performance improvements when appending keys at the end of the database
- The flags UPS_HINT_APPEND and UPS_HINT_PREPEND are now deprecated
- Removed the libuv dependency; switched to boost::asio instead
- Performance improvements when using many duplicate keys (with a duplicate table spanning multiple pages)
- Committed transactions are now batched before they are flushed to disk
- The integer compression codecs UPS_COMPRESSOR_UINT32_GROUPVARINT and UPS_COMPRESSOR_UINT32_STREAMVBYTE are now deprecated
- The integer compression codec UPS_COMPRESSOR_UINT32_MASKEDVBYTE is now a synonym for UPS_COMPRESSOR_UINT32_VARBYTE, but uses the MaskedVbyte library under the hood.
- Added Mingw compiler support (thanks, topilski)
All files are available on the download page.
Read More/CommentsFirst release of upscaledb-mysql 0.0.1
Posted on Sep 25, 21:23:03 CET 2016 - SHARE:
After several months of hard work, I'm proud to release the first (beta) version of upscaledb-mysql, a MySQL storage engine based on upscaledb.
MySQL uses "storage engines" to persist and access the actual table data. The most prominent storage engines are InnoDB and MyISAM. The upscaledb storage engine tries to be 100% compatible to InnoDB, while offering higher performance and an even faster NoSQL interface to the table data. If MySQL hits a performance wall you can use the regular upscaledb API, connect (via the remote interface) to the MySQL process and directly query or modify the data.
Performance
I have tested performance with several benchmark programs.
Sysbench 1.0
Sysbench’s OLAP test uses transactions which are not yet implemented [Scroll down for the TODO list]. To avoid race conditions, they were run with one client connection only. The tests were run for 60 seconds, the test data consists of 1 million rows. Tests were run with BEGIN/COMMIT transaction envelopes and with LOCK TABLE. The graphs show the total number of queries.
For such simple operations %%upscledb outperforms InnoDB.
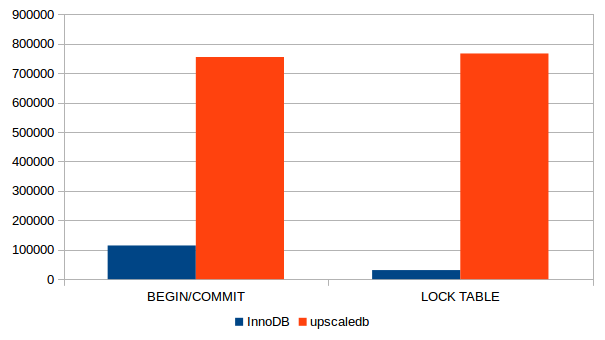
Benchmark results of sysbench 1.0 with and without transactions (1 mio rows)
Wordpress 4.3
I have run two benchmarks using siege, a http benchmark tool. The first one retrieves the start page of a Wordpress blog with five posts and several comments. The second benchmark searches the blog by accessing the “Search” page. Both tests were run for 30 seconds, with 30 concurrent connections.
The results are slightly in favour of InnoDB. Upscaledb leaves some performance on the table, mostly because it requires two database accesses when reading or writing a secondary index. In addition, InnoDB implements a MySQL feature called “Index Condition Pushdown”, which optimizes range lookups via secondary index. Both optimizations are on the TODO list.
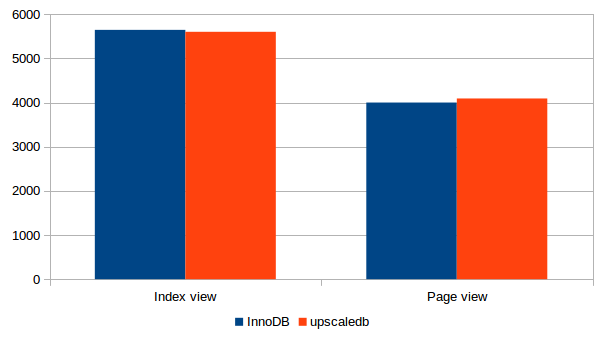
Benchmark results of wordpress 4.3
Remote NoSQL interface
Upscaledb does not yet optimize the COUNT(*) queries, therefore InnoDB is currently much faster. But upscaledb’s built-in query interface (“UQI”) is still the winner. This query interface can be extended through plugins, and any type of full-table scan can thus be implemented. In addition, you can use all other upscaledb API functions to read or manipulate the table data. The graphs show the duration of the SELECT COUNT(*) query (in seconds).
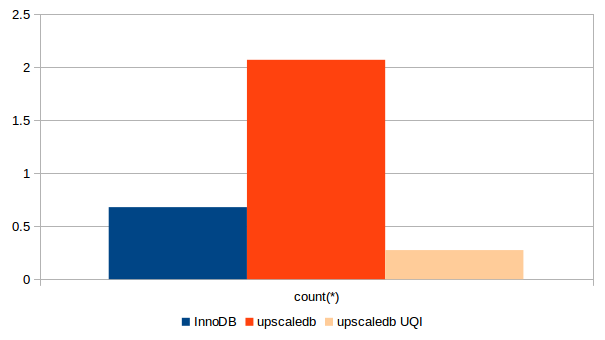
Benchmark results for a COUNT(*) query over 6mio rows
You can find detailled information about the benchmarks in a GitHub Gist.
Current status
The current version (0.0.1) is not yet ready for production. I'm not aware of critical bugs, but a few things are still on my TODO list (in no particular order):
- Support transactions (BEGIN/ABORT/COMMIT)
- Optimize count(*) and make it as fast as in InnoDB
- Make secondary indices a first-class citizen; currently, the index table stores the primary key, instead of directly referring to the blob with the row’s data
- Support Integer compression for indices
- Several internal storage engine functions are not yet provided
- Duplicate key performance (for non-unique indices) does not scale well
- Improve concurrency; upscaledb is single-threaded
- The MySQL feature "Index Condition Pushdown" is not yet supported
- The generated files sometimes are slightly larger than those of InnoDB; this needs to improve
- Charsets which are case-insensitive are not fully supported
- The installation procedure is very complex (If you can help w/ packaging please send me an email)
Installation and configuration
Both are described in the Wiki: Installation, Configuration.
Found a bug?
File an issue at the GitHub issue tracker. Please provide the following information:
- The versions of MySQL and upscaledb-mysql you are using
- The sequence of SQL commands which can be used to reproduce the bug
- The expected vs. the actual outcome
Frequently Asked Questions
Q: Is this ready for production?
A: No, unless your definition of "ready for production" is significantly different from mine.
Q: How can I improve the performance?
A: You can increase the cache size and tune various other
performance options.
See this page for documentation. Also, keep in mind:
- Small keys are faster than large keys
- Fixed-length keys are faster than variable-length keys
- Unique indices are faster than non-unique indices
Q: Does upscaledb use the same cache size as InnoDB?
A: Like InnoDB, upscaledb's default cache size is
128mb. However, this cache size is *per table*,
and not set globally! See this page for details, and make sure
you keep this in mind when comparing the performance of InnoDB and upscaledb.
Q: Is the NoSQL API security critical?
A: Yes, you basically open a backdoor to your
data and avoid all of MySQL's security layers
and authentication features. By default, this
interface is therefore switched off.
Q: How can I use the NoSQL API to access the various
columns?
A: You have to de-serialize the keys and records
that are stored. I'll cover this in another blog
post.
Q: Does the upscaledb storage handler support compression?
A: Yes, you can compress the row data with zlib,
snappy or lzf. See this page for more information.
Q: Does the upscaledb storage handler run with MariaDB?
A: I don’t know, I did not yet have time to test.
But I would expect so.
Follow me on Twitter!
Read More/Comments32bit integer compression algorithms - part 3
Posted on May 20, 18:55:21 CET 2016 - SHARE:
This is the third (and last) summary of a research paper by Daniel Lemire and me about the use of 32bit integer compression for keys in a B+-tree index. We evaluate a wide range of compression schemes, some of which leverage the SIMD instructions available in modern processors. To our knowledge, such a comparison has never been attempted before.
If you missed the previous blogs, you can find them here and here.
upscaledb is a parameterized B+tree, and the memory layout and algorithms of the B+tree nodes differ depending on the parameters the user chose when the database was created. If integer compression is enabled, then a specific "Compressed Integer Blocks" implementation is selected, which is further parameterized for each of the supported codecs.
However, adding integer compression (or ANY key compression) does not just affect the B+tree nodes. Other more generic algorithms (those that are independent from the parameterization) also have to be changed, e.g. how you insert or delete keys from the B+tree. In this article I want to describe those changes and how upscaledb's B+tree differs from the textbook algorithm.
When we started adding key compression to upscaledb, we encountered a few major problems that we had to solve.
Leaf node capacity as storage space
A textbook B+tree (or Btree, or any other derivate) defines its capacity as the number of keys that a node can store. Usually, a constant "k" is defined, and a node must store between k and 2k-1 items (otherwise it's underfilled and will be merged, or it overflows and will be split). (See Wikipedia for more information.)
But as soon as you add compression, there is no more "k" that you can use to describe the capacity. If you have a set of compressed keys, and you add a new one, you do not know in advance whether the key will fit into the available space or not. This depends on the codec, and on the "compressability" of the keys. When inserting a new key in a node with compressed keys, we found it therefore best to TRY the insertion. The codec would then decide whether the currently available space would be sufficient to store the new key, or not. If not, then the caller will attempt to reorganize the node in order to free up space. Only if this is impossible then the node is split.
This affects not just the B+tree node, but also the generic "insert" function (which is independent from the actual node format). It will simply attempt to insert the key, and split the node if insertion fails (and not if an arbitrary 2k-1 limit is reached).
Deleting keys can grow the storage
If you recall the codecs from part 1, we implemented one codec which is not "delete stable": BP128 (SimdComp). It compresses integers by bit-packing their deltas. Imagine the following sequence: 1, 2, 3, 4, 5, 6, 7, 8 (this is typical for an auto-incremented primary key). After encoding, all deltas can be stored in a single byte with all bits set (11111111). Now delete 4 and the delta of 3 and 5 will jump to 2. Each delta now requires 2 bits, and our storage grows to two bytes (the last two bits are unused): 01010110 01010100. In effect, our storage doubled although we deleted a key!
As a consequence, a B+tree node can run out of space if a key is deleted, and will require a node split.
This is such a weird scenario and so contrary to the textbook implementation that our first reaction was to avoid all codecs which behaved this way. Indeed, other researchers (like IBM for DB2) also had "delete stability" as a codec requirement. But after a while we discovered that it's possible to handle such cases - and changing the generic delete algorithm was fairly simple because it was very similar to the insert algorithm (see below).
Local balancing
Even before adding compression, upscaledb did not always follow the standard B+tree algorithm. Its insertion split the nodes on the way "down", when descending the tree, and not on the way "up", when returning from the recursion. This approach was first described by Guibas and Sedgewick. It's a much simpler approach. And deleting keys works similar: nodes are merged when "going down", not when going back up. Keys are never shifted. Underfilled nodes are accepted, and nodes are only merged when they are nearly empty, and if merging the node only has a local effect. If a merge would have to be propagated to more levels than just the parent, then the node will be left empty. This sounds wasteful, but is neglectable in practice.
The insert and delete operations are now very similar. In both cases the tree is descended, and internal nodes are merged or split if necessary. Only when the leaf is reached the operations diverge, and the new key is either inserted, or the old key is deleted.
If a split is necessary, a new node is allocated and the parent is updated. The split is never propagated because the parent node definitely has space for one more key (we made sure of that when descending the tree). The split only has a local effect.
Conclusion
It was definitely worth investing additional time to support BP128 (SimdComp) as a codec. BP128 offers the best compression ratio, especially for dense key ranges like auto-incremented primary keys or dense time stamps. Especially for analytical queries with upscaledb's query interface UQI.
Follow me on Twitter and get immediately notified when there are new announcements (like this one)!
Read More/Comments32bit integer compression algorithms - part 2
Posted on Apr 11, 19:12:27 CET 2016 - SHARE:
This blog post continues with the summary of a research paper by Daniel Lemire and me about the use of 32bit integer compression for keys in a B+-tree index. We evaluate a wide range of compression schemes, some of which leverage the SIMD instructions available in modern processors. To our knowledge, such a comparison has never been attempted before.
You can read part one here. This part describes the integration of integer compression in upscaledb and presents benchmark results.
The upscaledb B+-tree
upscaledb’s B+-tree node stores keys and values separately from each other. Each node has a header structure of 32 bytes containing flags, a key counter, pointers to the left and right siblings and to the child node. This header is followed by the KeyList (where we store the key data) and the RecordList (where we store the value’s data). Their layout depends on the index configuration and data types.
The RecordList of an internal node stores 64-bit pointers to child nodes, whereas the RecordList of a leaf node stores values or 64-bit pointers to external blobs if the values are too large.
Fixed-length keys are always stored sequentially and without overhead. They are implemented as plain C arrays of the key type, i.e., uint32 t keys[] for a database of 32-bit integers. Variable-length keys use a small in-node index to manage the keys. Long keys are stored in separate blobs; the B+-tree node then points to this blob.
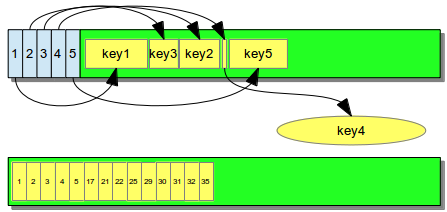
Memory layout for variable-length (top) and fixed-length keys (bottom)
This in-memory representation of fixed-length keys makes applying compression easy - at least in theory. The keys are already stored in sorted order, therefore applying differential encoding does not require a change in the memory layout. Since keys are stored sequentially in memory, SIMD instructions can be used efficiently if needed.
When using integer compression, the keys are split into blocks of up to 256 integers per block. We chose this to offer faster random access (by skipping blocks). Also, inserting or deleting values will only affect a small block instead of a huge one.
Codec requirements
I already described the various codecs in the previous part. In order to integrate a codec into upscaledb, it had to implement a few functions.
uncompress block
A full block is not decoded during CRUD (Create/Read/Update/Delete) operations, but it is decoded frequently during analytical queries (see below).
compress block
Used i.e. after a page split or in the "vacuumize" operation, which periodically compacts a node in order to save space (see below).
insert
Inserts a new integer value in a compressed block. A few codecs (Varbyte, MaskedVByte and VarIntGB) can do this without uncompressing the block. All other codecs uncompress the block, modify it and then re-compress the block.
append
Appending an index key at the “end” of the database is a very common operation, therefore we optimized it. Most codecs are now able to append extremely fast with O(1), and without decoding the whole block. Appending an integer key to a compressed block would otherwise be costly, because all codecs (except FOR and SIMD FOR) have to reconstruct all values because of the differential encoding.
search
Performs a lower-bound search in a compressed block, without decompressing it.
delete
Not a priority since we did not use this in our benchmark. Implemented for Varbyte (and therefore also for MaskedVByte) directly on the compressed data. All other codecs decode the block, delete the value and then re-encode the block again.
vacuumize
Performs a compaction by removing gaps between blocks. Gaps occur when keys are deleted and blocks therefore shrink, or blocks require more space and are moved to a different location in the node. SIMD FOR and BP128 periodically also decode all keys and re-encode them again.
(select)
Was originally used for cursor operations. But then we found out that cursors often access the same block. We decided to decode and cache the last used block. The select function is therefore no longer used.
Benchmarks
All our experiments are executed on an Intel Core i7-4770 CPU (Haswell) with 32 GB memory (DDR3-1600 with double-channel). The CPU has 4 cores of 3.40 GHz each, and 8 MB of L3 cache. Turbo Boost is disabled on the test machine, and the processor is set to run at its highest clock speed. The computer runs Linux Ubuntu 14.04. We report wall-clock time.
Insert
This benchmark creates a new database for 32bit integer keys and inserts various numbers of keys. We should expect a compressed database to be slower for such applications, as insertions may require complete recompression of some blocks, at least in the worst case. Among the compressed formats, the best insertion performance is offered by the FOR, SIMD FOR and Masked VByte codecs, followed by BP128 and VarIntGB. VByte is slower than all other codecs. If one uses FOR, SIMD FOR and Masked VByte, insertions in a compressed database are only 2.5× slower than insertions in an uncompressed database.
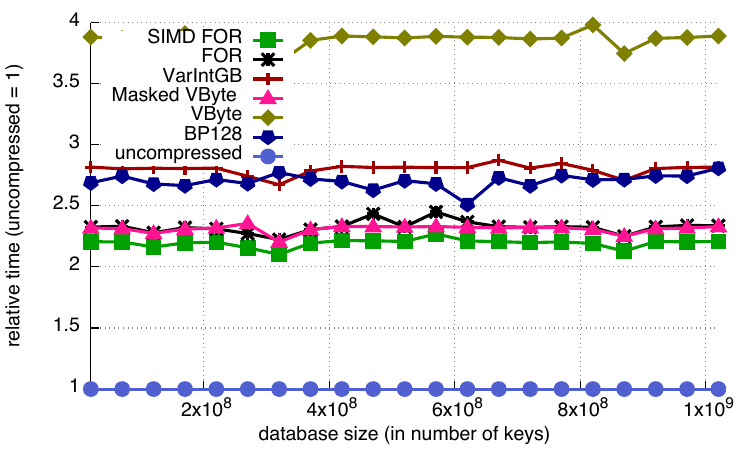
Relative insert timings
Look-ups
This benchmark opens an existing database and performs point look-ups of all inserted keys. Each look-up requires a B+-tree traversal to the leaf node. The node then performs a linear search through the block index and locates the block which stores the requested key. The codec then searches the block for the key.
The benchmarks show that integer compression does not cause a significant performance hit for lookup operations. We get the best results with SIMD FOR, VarIntGB and FOR, and the worst results with VByte and BP128 (with a penalty of up to 60 %). Actually this was a positive surprise; we expected worse!
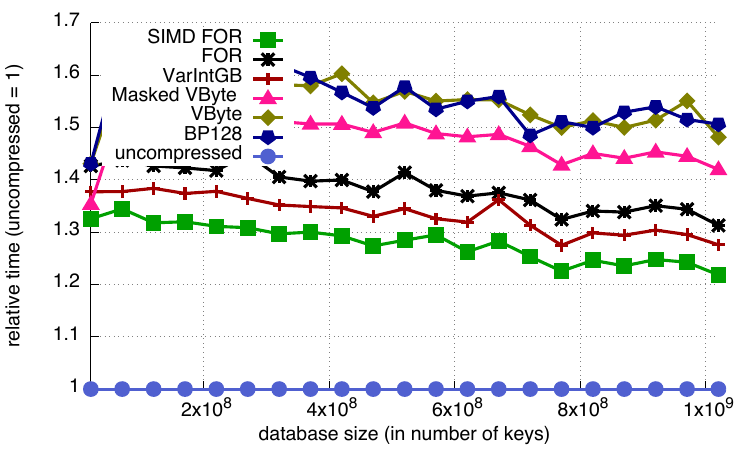
Relative look-up timings
Cursors
This benchmark opens an existing database and creates a cursor to traverse from the first to the last key. To position itself on the first key, the cursor traverses down the B+-tree at the left-most path down to the leaf, then visits each leaf. Since all leaf nodes are linked, no further traversal is required.
In our original implementation, the cursor then used the select method to retrieve the key directly from the compressed block. But since cursors are usually used for sequential access, and therefore frequently access the same block, we decided to decode the block and cache the decoded values. Our tests showed a significant performance improvement compared to the previous implementation based on select.
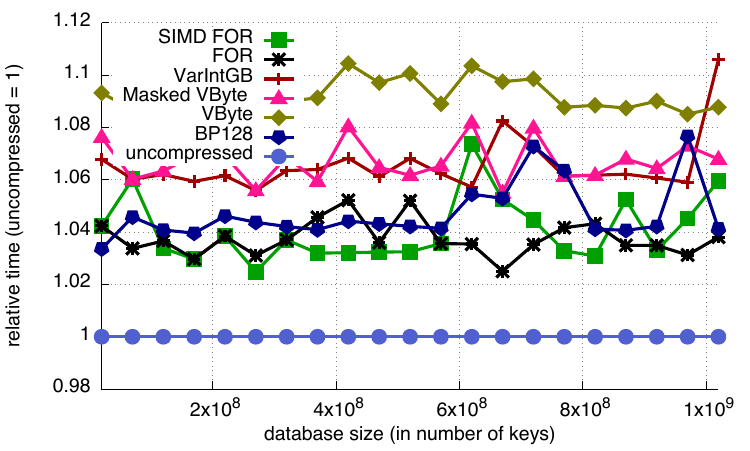
Relative cursor timings
Sum
This benchmark performs a “SUM” operation on all keys. It is equivalent to a SELECT SUM(column) operation of a SQL database, where the specified column is an index of unique 32bit integer keys. For such operations, upscaledb does not use a cursor to traverse the B+-tree, but performs the operation directly on the B+-tree’s data, without copying the keys into the application’s memory. SUM performance is impacted by database size: the bigger the database, the more compression is beneficial, with BP128 and SIMD FOR offering the best performance.
Relative SUM timings
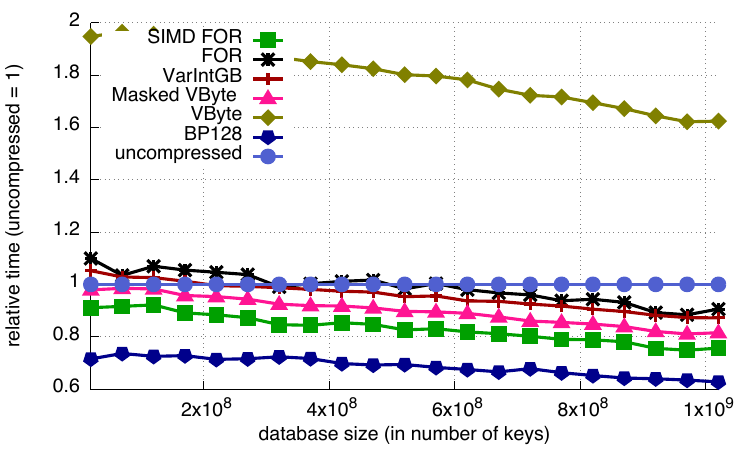
File sizes
Finally, here are the compression results with the various database sizes, using the default block sizes (128 for BP128 and 256 for other codecs). BP128 is the clear winner. It is able to compress the database by a factor of ten compared to an uncompressed B+-tree. The compression ratios offered by the other codecs are similar (compression ratio of 2 or 3), with SIMD FOR compressing slightly less and VByte compressing slightly better.
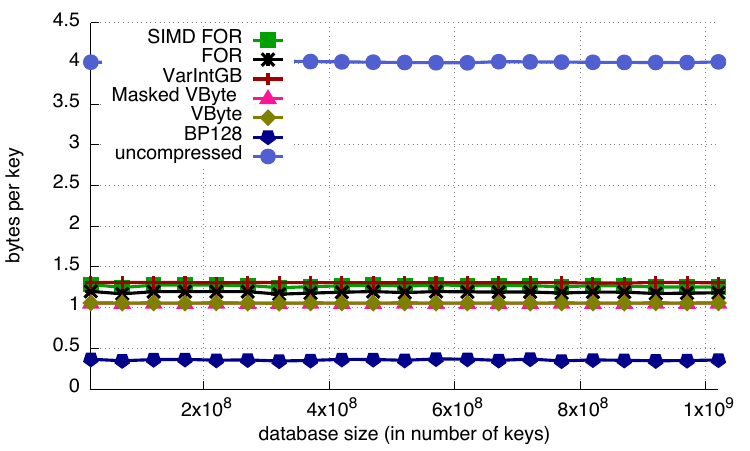
Relative database sizes
Conclusion
We have shown that fast key compression could improve the single-threaded performance of a key-value store - if these compression techniques are accelerated with SIMD instructions. We get the best performance for SIMD codecs (BP128 and SIMD FOR). Unlike other codecs, they show an ability to noticeably improve query performance in all our tests (from small to large databases) on the analytic “SUM” benchmark.
Another conclusion would be: if your application mostly appends keys (instead of inserting them at random positions), and you perform many analytical queries or full-table scans, then performance will improve (in the best case) or at least not deteriorate significantly (in the worst case). But you will save lots of RAM.
One of our codecs, BP128 ("SimdComp"), comes with an interesting limitation: it is not "delete stable" and often grows when keys are deleted. To our knowledge, upscaledb is the only database which is able to deal with such codecs. In the next blog I'll describe how we did this, a few other problems we faced when we integrated compression, and how upscaledb's B+-tree differs from the textbook B-tree algorithm. Sign up to our newsletter to get notified when the next blog is published.
Follow me on Twitter!
Read More/CommentsFast range queries in upscaledb
Posted on Mar 22, 18:38:21 CET 2016 - SHARE:
This blog post shows how to use the new "UQI" query interface of upscaledb 2.2.0. It's the follow-up to the series "Building an embedded column store database with upscaledb" (part one, part two and part three).
In the previous parts I demonstrated how to use upscaledb to create multiple indexes on one or several columns, and how to perform range queries with cursors. This part will show how to run queries with the UQI query interface.
More analytical functions: "UQI"
upscaledb has a lot to offer regarding analytics: it has a full set of APIs dedicated to analytical calculations. These APIs are called "UQI" (Upscaledb Query Interface) and declared in the header file `ups/upscaledb_uqi.h`. These functions were rewritten for version 2.2.0 and now support an SQL-ish query language which can be extended through custom plugins.
This query interface can run full-table scans over a single database and apply aggregation functions and filter predicates. Functions and predicates can be extended through user-supplied plugins. Joins are not supported.
Internally, the UQI functions can operate directly on the B+-tree node data. B+-trees store keys and records very compact and efficiently. While you could also use cursors to implement this functionality, a cursor requires the key- and record data to be copied from the B+-tree to the application. The new UQI interface does the opposite: it performs the query in the B+-tree and does not copy any data. This makes the UQI queries much faster.
Here is a list of the most important APIs:
uqi_select
Performs a "select" query. The query syntax is described below. Results
are returned in result. This is a shortcut for uqi_select_range.
UPS_EXPORT ups_status_t UPS_CALLCONV uqi_select(ups_env_t *env, const char *query, uqi_result_t **result);
uqi_select_range
Performs a "select" query. If begin is not NULL then the query
starts at the specified position, otherwise it starts at the beginning of the
database. Afterwards, the begin cursor is advanced to the next
element after end. If end is not NULL then the query
stops at the specified position, otherwise it stops at the end of the database.
This API can be used for pagination.
UPS_EXPORT ups_status_t UPS_CALLCONV
uqi_select_range(ups_env_t *env, const char *query, ups_cursor_t *begin,
const ups_cursor_t *end, uqi_result_t **result);
uqi_result_get_row_count
Returns the number of rows from a result object.
UPS_EXPORT uint32_t UPS_CALLCONV uqi_result_get_row_count(uqi_result_t *result);
uqi_result_get_key_type
Returns the key type from a result object. Key types are
UPS_TYPE_UINT8, UPS_TYPE_UINT32,
UPS_TYPE_BINARY etc.
UPS_EXPORT uint32_t UPS_CALLCONV uqi_result_get_key_type(uqi_result_t *result);
uqi_result_get_record_type
Returns the record type from a result object. Record types are
UPS_TYPE_UINT8, UPS_TYPE_UINT32,
UPS_TYPE_BINARY etc.
UPS_EXPORT uint32_t UPS_CALLCONV uqi_result_get_record_type(uqi_result_t *result);
uqi_result_get_key
Returns a key from the specified row of an result object. I.e. uqi_result_get_key(&result, 0, &key); returns the first key from the query results.
UPS_EXPORT void UPS_CALLCONV uqi_result_get_key(uqi_result_t *result, uint32_t row, ups_key_t *key);
uqi_result_get_record
Returns a record from the specified row of an result object. I.e. uqi_result_get_record(&result, 0, &record); returns the first record from the query results.
UPS_EXPORT void UPS_CALLCONV uqi_result_get_record(uqi_result_t *result, uint32_t row, ups_record_t *record);
uqi_result_get_key_data
Returns the serialized key data. If the key type has fixed length (i.e. UPS_TYPE_UINT32) then the returned pointer can be casted directly into a uint32_t * pointer. The size returns the size of the integer array.
UPS_EXPORT void *UPS_CALLCONV uqi_result_get_key_data(uqi_result_t *result, uint32_t *size);
uqi_result_get_record_data
Returns the serialized record data. If the record type has fixed length (i.e. UPS_TYPE_UINT32) then the returned pointer can be casted directly into a uint32_t * pointer. The size returns the size of the integer array.
UPS_EXPORT void *UPS_CALLCONV uqi_result_get_record_data(uqi_result_t *result, uint32_t *size);
UQI examples
The query format is simple and mostly self-explanatory. Key words are not case sensitive. Here are a few examples:
Counting things
Calculates the sum of all keys from database 1
SUM($key) from database 1
Counts all keys in database 13
count($key) from database 13
Counts all distinct keys in database 13 (see below for the meaning of 'distinct', which differs from a standard SQL database)
distinct count($key) from database 13
Counts all distinct keys in database 13 with even records (the "even" predicate has to be supplied by the user)
distinct count($key) from database 13 where even($record)
Summing up
Note that you can only SUM up records (or keys) if their type is numeric!
SUM($key) from database 1
SUM($record) from database 1
TOP-k and BOTTOM-k
The TOP and BOTTOM queries are the only queries which accept the LIMIT keyword. If you specify a LIMIT for any other function the the UQI parser will currently fail with an error. You can also query TOP/BOTTOM queries over the keys, but since keys are already sorted it would be much cheaper to use a cursor instead (with the BOTTOM elements starting at the beginning of the database, and the TOP elements at the end).
TOP($record) from database 1 LIMIT 20
BOTTOM($record) from database 1 LIMIT 10
Min and Max
Again you can calculate the minimum and maximum from keys as well (by using MIN($keys) from database 1), but since keys are already sorted it would be much more efficient to use a cursor and retrieve the first (or last) element in the database.
MIN($record) from database 1
MAX($record) from database 1
Using predicates
A predicate can be supplied with the WHERE clause. In
release 2.2.0 there are no predicates supplied, but they can
be written as a plugin. A predicate can also be loaded from an external (dynamic) library.
Counts all distinct keys in database 13 with even records. The "even" predicate is loaded from a dynamic library, and therefore has to be quoted.
distinct count($key) from database 13 where "even@plugin.so"($record)
The "distinct" keyword ignores duplicate keys and skips them when processing the input data. Its meaning is therefore different from DISTINCT in an SQL database, where it filters duplicate results.
Creating custom aggregation and predicate functions
For performance reasons, plugins have to be written in C or C++. With some knowledge in C/C++, writing a plugin is not difficult, but it extends the scope of this blog post a bit. We've created a sample which demonstrates how an application can supply its own plugins for aggregating and filtering data: uqi2.c.
The UQI interface is brand new, and fairly unique. If you have any questions then please do not hesitate to write!
Read More/CommentsLatest Posts
Release of upscaledb 2.2.1
Sep 25, 21:23:03 CET 2016
First release of upscaledb-mysql 0.0.1
May 20, 18:55:21 CET 2016
32bit integer compression algorithms - part 3
Apr 11, 19:12:27 CET 2016
32bit integer compression algorithms - part 2
Mar 22, 18:38:21 CET 2016
Fast range queries in upscaledb
Apr 03, 22:26:51 CET 2016
Release of upscaledb 2.2.0