About Features and Architecture
What is upscaledb?
upscaledb is an embedded key/value database engine. "Embedded" means that as a software developer, you can link it directly into your application. A variety of programming environments is supported. The upscaledb library is developped in C/C++, but can be used from .NET, Java, Erlang, Elixir and Python.
upscaledb stores a set of databases (sorted key/value lists) in a single file, or in-memory. The databases are optimized for fast reads and writes, and even faster scans.
Each database is stored in a B-Tree index structure. These tree-like structures automatically sort the keys, and are optimized for fast reads and writes. In addition, upscaledb B-Trees are parameterized, which means that you can configure a database to store specific keys and values (strings, integers etc). The B-Tree will then be optimized for this type.
The configured type allows upscaledb to perform analytical calculations like SUM, AVERAGE and COUNT directly in the B-Tree, without copying the key/value pairs to the application.
In addition, upscaledb supports ACID transactions, transparent encryption, compression an many other features that help you to create powerful applications without worrying about your data.
B-Tree architecture
The B-Tree is upscaledb's most important data structure. Each database is stored as a B-Tree.
A B-Tree is a hierarchical structure where each internal node of the tree stores keys and pointers to child nodes, and each leaf of the tree stores keys and their record(s). In upscaledb, each node stores keys and records (or pointers) separated from each other. The node starts with a few bytes of metadata, followed by the keys (the KeyList), then the records (in the RecordList).
The memory layout of a B-Tree node: the metadata stores
pointers to the left and right B-Tree siblings.

The B-Tree is parameterized; its algorithms and data structures are optimized for the data types specified by the user. A B-Tree configured for 32bit integer keys uses a completely different storage layout for its KeyList than one for variable length string keys. And a RecordList for fixed length records of 8 bytes stores its records directly in the B-Tree leaf whereas a RecordList for variable length records can allocate storage from reserved "blob pages" in the file.
This layout has many advantages. When traversing pages (or searching for a specific key), more keys are loaded into the CPU cache and the CPU can process those keys faster. Keys can be compressed efficiently, and for some key types (e.g. 32bit integer keys), SIMD instructions can be used to process multiple keys at once. The storage layout is very compact and often does not require any metadata for the keys. This reduces the file size and the memory requirements. More data can be stored in memory, and less I/O is required to process the file.
Variable length keys
For databases which use string keys or binary keys of different length, the B-Tree creates KeyLists with a dedicated storage layout. This layout starts with a small in-node index which stores size and offset of a range. The range stores the key data. If the key data is too large then the key is stored in a separate blob - just like a regular record. Unused ranges (e.g. of deleted keys) are re-used as soon as new keys are inserted.
The memory layout of a KeyList for keys of variable length.
A small in-node index stores offset and size of its
data range. Large keys ("key4") are not stored in the node
but in an external blob.
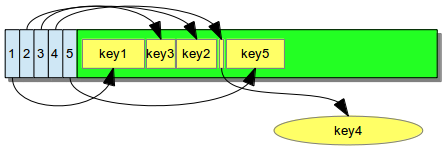
The in-node index allows fast random access, and therefore keys can be searched efficiently (a binary search algorithm is used for looking up keys in a KeyList). Inserting keys at random positions usually requires shifting index entries "to the right" in order to create space for the new index, but often the key's data is appended at the end of the data section and therefore does not require moving memory around.
Fixed length keys
This is the most efficient and compact storage layout and is used for the following keys:
- 8, 16, 32 or 64bit integer keys
- 32 or 64bit floating point keys
- fixed length binary keys
The KeyList is implemented as an array
of the specified type, without any additional metadata. E.g.
for 32bit integer keys the C type uint32_t keys[]
is used, and binary keys of fixed length are stored in a
flat uint8_t keys[] array.
The memory layout of a KeyList for fixed length 32bit
integer keys. No metadata is required; the integer
keys are organized as a plain uint32_t array.

Looking up fixed-length keys is implemented with a very fast binary search algorithm. Inserting or deleting keys usually requires moving memory, which is very fast on modern CPUs. Appending keys is even faster, breaking speed limits at several million keys per second on commodity hardware.