32bit integer compression algorithms by Christoph Rupp
Posted on Mar 08, 21:02:54 CET 2016 - SHARE:
This blog post is a summary of a research paper by Daniel Lemire and me about the use of 32bit integer compression for keys in a B+-tree index. We evaluate a wide range of compression schemes, some of which leverage the SIMD instructions available in modern processors. To our knowledge, such a comparison has never been attempted before.
The paper was submitted to a journal and is currently in review. We started writing in August 2014 and finished the first version in December 2015.
Our paper evaluated implementations of the most common codecs. First we showed micro benchmarks of the codecs, then added them to upscaledb to compress the keys. In upscaledb, a database key is "typed". Integer keys are stored in a plain integer array (uint32_t[]). The keys can therefore be optimally compressed, and it's even possible to use SIMD instructions.
Since the keys are sorted, most codecs also use differential encoding. Instead of storing the original values, only the differences between the values is stored. The sequence N1, N2, N3, N4, ... Nn is then stored as N1, N2 - N1, N3 - N2, N4 - N3, ... Nn - Nn-1. Differential encoding stores smaller values and therefore has more efficient compression.
We implemented additional operations directly on the compressed data, without decompression. Such operations include lower-bound searches and selecting values at a specific position; some codecs even can insert values without decompressing the sequence.
This is the first blog post, focussing only on the codecs. Another blog post will follow where I will present the results from the upscaledb integration.
The Codecs
VByte
VByte (or var-byte, varint, variable-byte) is one of the most popular and established integer compression techniques. It is used, for example, in Google's Protocol Buffer and Apache Lucene. Small numbers (< 127) are stored in a single byte. If the number is larger, a "continuation bit" is set, and an additional byte is used. Here are a few examples:
Decimal Binary Variable Byte encoded
127 00000000 01111111 01111111
128 00000000 10000000 10000000 00000000
16384 01000000 00000000 10000000 10000000 00000001
Our VByte implementation uses standard C code. It is very efficient if many integers fit in a single byte, and since we use delta compression this is often the case. One can then decode over a billion integers per second on commodity superscalar desktop processors. However, the performance can be lower when integers fit in various numbers of bytes, as the cost of branch mispredictions increases.
VByte is a very simple format, and it is possible to implement fast select and sequential searches without first decompressing all integers. It is even possible to insert keys directly into the compressed data.
VarIntGB (or Group Varint)
To overcome the performance problems of VByte, Google created the VarIntGB format (here is Jeff Dean's presentation). It can encode and decode blocks of four integers instead of one integer at a time. It works by storing the sizes of up to four integers in a single byte (two bits per size).
01-00-00-01 | 0x0004 | 0x0c | 0x0a | 0x0200
Encoded bytes corresponding to integers 1024, 12, 10, 512.
The result occupies seven bytes.
Like VByte, implementing a fast select or a fast sequential search over VarIntGB is straightforward. However, a fast insertion is more difficult. When inserting a value at index i, the previous values do not have to be rewritten. But all the remaining values have to be recoded. We found it more appropriate to decompress the remaining values, and then recompress them with the new value added.
Masked VByte
VByte decoders process one input byte at a time. Masked VByte is a very fast SIMD-based decoder which is able to decode many integers at a time. The Masked VByte decoder first collects all the most significant bits using the ‘pmovmskb’ instruction. These bits are then used as an index in a precomputed lookup table, which stores masks for the ‘pshufb’ instruction. pshufb permutes the bytes of a register. Finally, we need to mask or shift the permuted bytes to arrive at the decoded integers.
Masked VByte can be three times faster than a conventional VByte decoder when the data is sufficiently compressible. Masked VByte also benefits from an integrated SIMD-accelerated differential coding.
We implemented accelerated select and sequential search functions that are similar to the VByte functions. Selection is SIMD-accelerated: we decode in registers the first 4 i/4 values and return the value at the proper index. Sequential search is handled similarly. For the insertion, we use the same function as for VByte: this is possible because the underlying data format is identical.
Binary Packing (BP128/SimdComp)
Binary Packing fetches the maximum m of an integer sequence and then stores all integers of this sequence in log2(m+1) bits (in plain English: in as many bits as required to store the maximum value). If differential coding is used, the maximum can be relatively low, and sometimes only a few bits are required.
Our BP128 implementation uses SIMD instructions to efficiently decode a block of 128 integers. It uses differential coding, and we implemented a fast select function and a sequential search function. Insertions require decoding the entire array.
Frame of Reference
Frame of Reference (or FOR) is the only technique listed here that does not use differential coding. The downside of differential coding is that it is difficult to skip to a random index, because each value has to be reconstructed from the previous delta. FOR offers good compression and has fast random access. Its select function is very fast, and we implemented binary searches which are faster than the linear searches of the other codecs.
In FOR, the minimum value of an integer sequence is used as a reference for all other values. The sequence N1, N2, N3, N4 is encoded as N1, N2 - N1, N3 - N1, N4 - N1 etc. To decode these values, we need the minimum and then compute the sums. Since our arrays are sorted, the minimum is always at the beginning.
We evaluated two FOR libraries: the scalar libfor implementation, and SIMD-FOR, using SIMD instructions similar to BP128. Both are not compatible. Both implement select and search functions without decompressing the data. Inserting a new value can be done by uncompressing the block, inserting the value in the uncompressed data and then recompressing it.
Micro Benchmarks
Our micro benchmarks were run without database interaction. We compile our C++ benchmarking software using the GNU GCC 4.8.2 compiler with the -O3 flag. Our implementation is freely available under an open-source license.
All our experiments are executed on an Intel Core i7-4770 CPU (Haswell) with 32 GB memory (DDR3-1600 with double-channel). The CPU has 4 cores of 3.40 GHz each, and 8 MB of L3 cache. Turbo Boost is disabled on the test machine, and the processor is set to run at its highest clock speed. The computer runs Linux Ubuntu 14.04. We report wall-clock time.
Compression ratios
Given a bit width b ≤ 24, we first generate an array of 256 sorted 32-bit integers. We see that BP128 offers the best compression whereas FOR and SIMD-FOR offer poorer compression compared to other codecs.
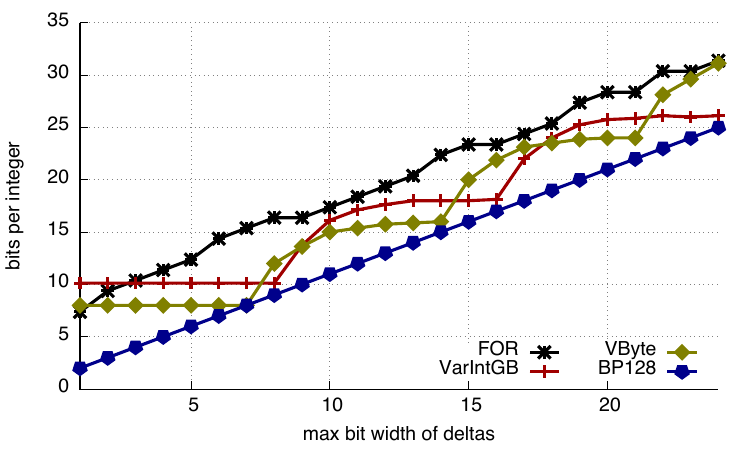
Bits per integer - compression ratios
Decompression
Decompression speed is plotted in billions of integers per second. SIMD-FOR is twice as fast as the next scheme, BP128, which is itself much faster than most other alternatives (up to twice as fast). VByte is the only codec that is limited by a best speed of only about 1 billion integers per second. In contrast, SIMD-FOR can decompress data at a rate of over seven billion integers per second – or about two integers decoded per clock cycle.
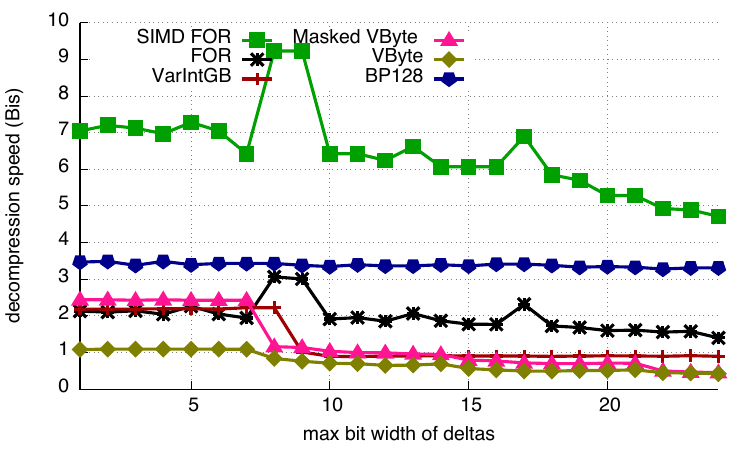
Decompression speed
Search
We benchmark the search function by randomly seeking a value in range. VByte is significantly slower than the other codecs. VarIntGB offers the best performance in this case. FOR and SIMD-FOR differ from the other schemes in that they use a binary search (as a sequential search proved slower) whereas all other codecs shown here rely on a sequential search. If the block size was much larger, FOR and SIMD-FOR could be expected to perform better, but we are not interested in that case.
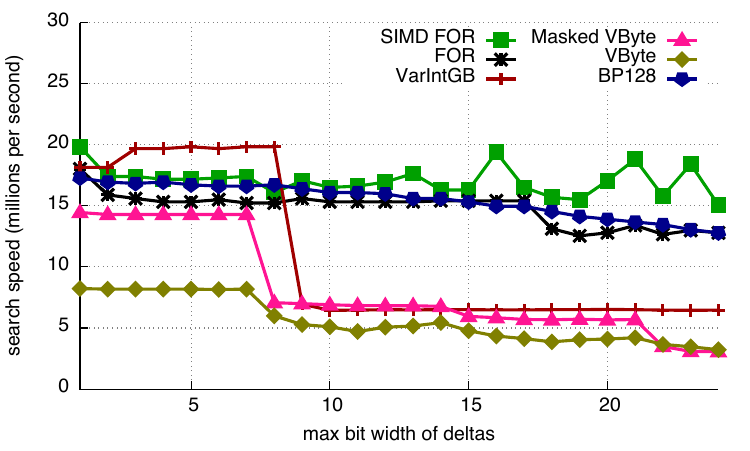
Search speed
Select
We randomly select the value at one of the indexes. We present the data in millions of operations per second with a logarithmic scale. We see that FOR and SIMD-FOR are an order of magnitude faster at this task because they do not rely on differential coding. BP128 is the next fastest codec while VByte is the slowest.
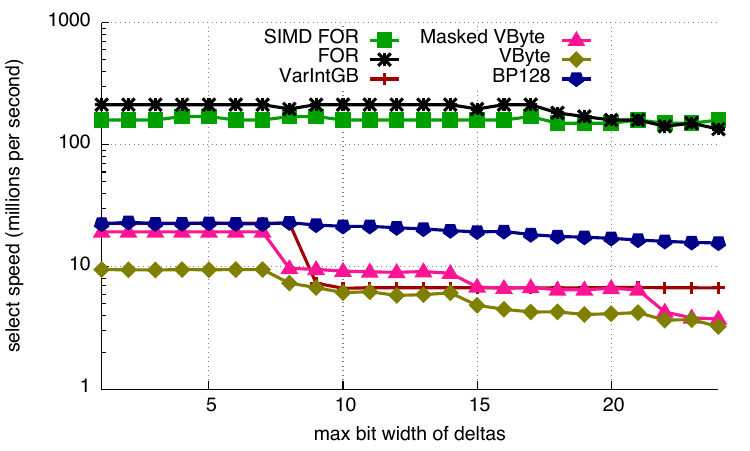
Select speed
Conclusion
Overall, our results suggest that on speed and compression ratios, BP128 offers good performance. If faster random access is necessary, and the compression ratio is not an issue, then FOR and SIMD-FOR might be preferable.
In part two I will write about integrating key compression in the upscaledb B+-tree, describe the challenges we faced and show more benchmarks. Follow me on Twitter!
Latest Posts
Release of upscaledb 2.2.1
Sep 25, 21:23:03 CET 2016
First release of upscaledb-mysql 0.0.1
May 20, 18:55:21 CET 2016
32bit integer compression algorithms - part 3
Apr 11, 19:12:27 CET 2016
32bit integer compression algorithms - part 2
Mar 22, 18:38:21 CET 2016
Fast range queries in upscaledb
Apr 03, 22:26:51 CET 2016
Release of upscaledb 2.2.0