First release of upscaledb-mysql 0.0.1 by Christoph Rupp
Posted on Sep 25, 21:23:03 CET 2016 - SHARE:
After several months of hard work, I'm proud to release the first (beta) version of upscaledb-mysql, a MySQL storage engine based on upscaledb.
MySQL uses "storage engines" to persist and access the actual table data. The most prominent storage engines are InnoDB and MyISAM. The upscaledb storage engine tries to be 100% compatible to InnoDB, while offering higher performance and an even faster NoSQL interface to the table data. If MySQL hits a performance wall you can use the regular upscaledb API, connect (via the remote interface) to the MySQL process and directly query or modify the data.
Performance
I have tested performance with several benchmark programs.
Sysbench 1.0
Sysbench’s OLAP test uses transactions which are not yet implemented [Scroll down for the TODO list]. To avoid race conditions, they were run with one client connection only. The tests were run for 60 seconds, the test data consists of 1 million rows. Tests were run with BEGIN/COMMIT transaction envelopes and with LOCK TABLE. The graphs show the total number of queries.
For such simple operations %%upscledb outperforms InnoDB.
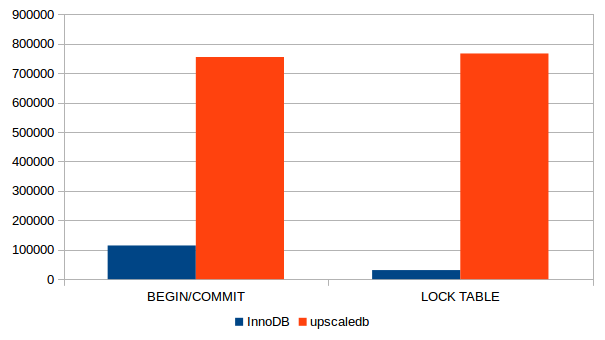
Benchmark results of sysbench 1.0 with and without transactions (1 mio rows)
Wordpress 4.3
I have run two benchmarks using siege, a http benchmark tool. The first one retrieves the start page of a Wordpress blog with five posts and several comments. The second benchmark searches the blog by accessing the “Search” page. Both tests were run for 30 seconds, with 30 concurrent connections.
The results are slightly in favour of InnoDB. Upscaledb leaves some performance on the table, mostly because it requires two database accesses when reading or writing a secondary index. In addition, InnoDB implements a MySQL feature called “Index Condition Pushdown”, which optimizes range lookups via secondary index. Both optimizations are on the TODO list.
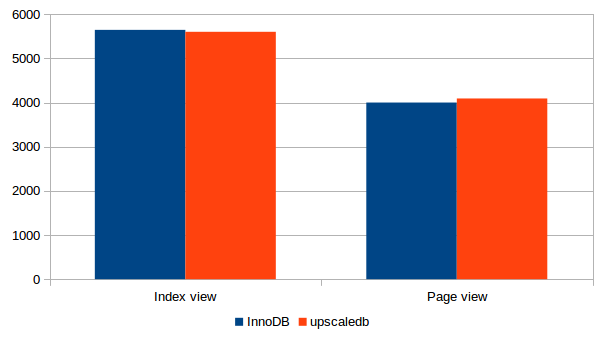
Benchmark results of wordpress 4.3
Remote NoSQL interface
Upscaledb does not yet optimize the COUNT(*) queries, therefore InnoDB is currently much faster. But upscaledb’s built-in query interface (“UQI”) is still the winner. This query interface can be extended through plugins, and any type of full-table scan can thus be implemented. In addition, you can use all other upscaledb API functions to read or manipulate the table data. The graphs show the duration of the SELECT COUNT(*) query (in seconds).
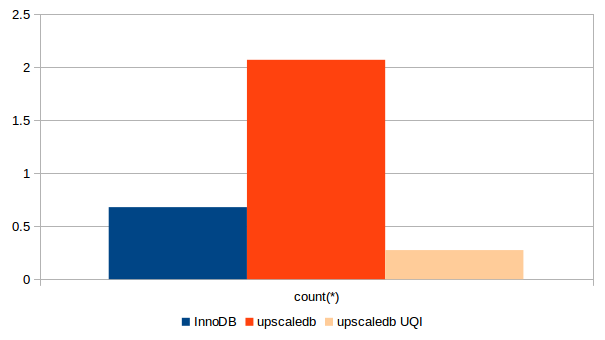
Benchmark results for a COUNT(*) query over 6mio rows
You can find detailled information about the benchmarks in a GitHub Gist.
Current status
The current version (0.0.1) is not yet ready for production. I'm not aware of critical bugs, but a few things are still on my TODO list (in no particular order):
- Support transactions (BEGIN/ABORT/COMMIT)
- Optimize count(*) and make it as fast as in InnoDB
- Make secondary indices a first-class citizen; currently, the index table stores the primary key, instead of directly referring to the blob with the row’s data
- Support Integer compression for indices
- Several internal storage engine functions are not yet provided
- Duplicate key performance (for non-unique indices) does not scale well
- Improve concurrency; upscaledb is single-threaded
- The MySQL feature "Index Condition Pushdown" is not yet supported
- The generated files sometimes are slightly larger than those of InnoDB; this needs to improve
- Charsets which are case-insensitive are not fully supported
- The installation procedure is very complex (If you can help w/ packaging please send me an email)
Installation and configuration
Both are described in the Wiki: Installation, Configuration.
Found a bug?
File an issue at the GitHub issue tracker. Please provide the following information:
- The versions of MySQL and upscaledb-mysql you are using
- The sequence of SQL commands which can be used to reproduce the bug
- The expected vs. the actual outcome
Frequently Asked Questions
Q: Is this ready for production?
A: No, unless your definition of "ready for production" is significantly different from mine.
Q: How can I improve the performance?
A: You can increase the cache size and tune various other
performance options.
See this page for documentation. Also, keep in mind:
- Small keys are faster than large keys
- Fixed-length keys are faster than variable-length keys
- Unique indices are faster than non-unique indices
Q: Does upscaledb use the same cache size as InnoDB?
A: Like InnoDB, upscaledb's default cache size is
128mb. However, this cache size is *per table*,
and not set globally! See this page for details, and make sure
you keep this in mind when comparing the performance of InnoDB and upscaledb.
Q: Is the NoSQL API security critical?
A: Yes, you basically open a backdoor to your
data and avoid all of MySQL's security layers
and authentication features. By default, this
interface is therefore switched off.
Q: How can I use the NoSQL API to access the various
columns?
A: You have to de-serialize the keys and records
that are stored. I'll cover this in another blog
post.
Q: Does the upscaledb storage handler support compression?
A: Yes, you can compress the row data with zlib,
snappy or lzf. See this page for more information.
Q: Does the upscaledb storage handler run with MariaDB?
A: I don’t know, I did not yet have time to test.
But I would expect so.
Follow me on Twitter!
Latest Posts
Release of upscaledb 2.2.1
Sep 25, 21:23:03 CET 2016
First release of upscaledb-mysql 0.0.1
May 20, 18:55:21 CET 2016
32bit integer compression algorithms - part 3
Apr 11, 19:12:27 CET 2016
32bit integer compression algorithms - part 2
Mar 22, 18:38:21 CET 2016
Fast range queries in upscaledb
Apr 03, 22:26:51 CET 2016
Release of upscaledb 2.2.0