About Features and Architecture
Compression
upscaledb implements several optional compression codecs that can be used to reduce the memory requirements, ultimately allowing one to store more data in RAM and avoiding disk I/O when scanning the B-Tree index.
Variable length keys can be compressed with Snappy, Zlib or lzf. These codecs work well with long keys that are well compressible, e.g. words from natural languages or long file path names.
32bit integer keys can be compressed with various codecs, many of them SIMD accelerated. These codecs use differential encoding, which means that only the delta from the previous key to the next key is stored. The resulting numbers are very small and require only a few bits of storage. In the best case, only one bit per key is required and the KeyList size shrinks nearly by factor 32 compared to an uncompressed index.
Records and the database journal can be compressed transparently with Snappy, Zlib or lzf.
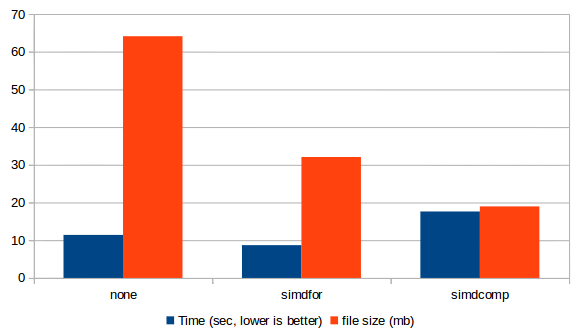
Performance of inserting 10 million random integer keys
into an index, with and without compression.
Analytics
Analytical functions like SUM,
COUNT and AVERAGE are provided
by built-in APIs. Unlike their SQL counterparts
they do not operate on records but on keys only. Users
usually create secondary indices on specific columns to enable
these functions.
Internally, these functions operate directly in the B-Tree's context. They process many keys at once and are extremely fast, handling up to several million keys in a split second on commodity hardware.
Cursors
Cursors can be used to bi-directionally traverse over the whole B-Tree, either for full table scans or for range scans. They are very fast and usually neither require I/O nor a B-Tree traversal when moving back and forth.
Cursors can also be used to locate keys that are not just
equal to a search key, but are greater (>),
greater or equal (≥), lower (<)
or lower or equal (≤) than a specified
key.
This allows users to perform range queries that start "somewhere" in the database, even if the exact key is not known.