Building an embedded column store database with upscaledb - part 2 by Christoph Rupp
Posted on Jan 29, 22:03:23 CET 2016 - SHARE:
In the first part of this series I have described the ideas behind "row oriented" and "column oriented" databases. This part will delve even deeper.
OLAP vs OLTP, or: Column Oriented vs Row Oriented
You might have seen the terms OLAP and OLTP before. OLAP is an abbreviation for OnLine Analytical Processing, and this basically means what was described in part 1: full-table scans with analytical calculations. An example would be to calculate the average salary of all employees, the monthly sum of all incoming orders for a dashboard, the 10 top scorers of your favourite sports league etc.
OLTP, in contrast, is about OnLine Transactional Processing: short read/write operations. A typical example is the shopping cart of an online warehouse. If a visitor "adds" an item to her shopping cart then a short transaction with a few write operations will update the database.
As mentioned previously, upscaledb users have the choice between a column oriented and a row oriented data representation. Of course you can also build hybrid databases where data is stored row oriented, with a few additional indexes for running analytical queries or fast lookup operations.
Optimizing for OLTP
Short read and write operations are fastest if as few indexes as possible have to be updated. In best case, there is only one index (which is as small as possible), and the record data.
In order to make inserts and lookups as fast as possible, it is really essential to reduce your data size as much as possible! It will make a huge difference if you store a timestamp as a 32bit number (number of seconds since 1.1.1970), or as a string in YYYYMMDDhhmmss format, especially if this timestamp is used as the index key.
If records are very small then upscaledb will store those records in the Btree leaf; otherwise it will allocate a "blob" somewhere in the file and store the record there. Just how small do those records have to be in order to get stored in the Btree leaf? That's up to upscaledb to decide, and it also depends on the page size and the key size. You can use `ups_bench` to run a simulation, then use `ups_info` on the generated database and it will print whether records are stored as blobs or not.
Optimizing for OLAP
Long queries and full table scans require lots of I/O, therefore it is important to reduce the size of the data as much as possible. As outlined in part 1 of this series, column store databases reduce the data size that is required for a scan by storing only a single attribute in a Btree node, and many offer additional compression of these nodes.
There are many compression algorithms optimized for the different data types, i.e. bitmap compression, prefix compression, heavy weight compression (using compression algorithms like LZO, LZF), dictionary compression etc. upscaledb implements some of these.
In order to optimize for analytical queries, you should create indexes for all those attributes that you want to query. Make sure that your databases are configured for the data type of this attribute, i.e. specify a key type (`UPS_KEY_UINT32`, `UPS_KEY_UINT64` etc). Since all those indexes just offer an indirection to the primary key, you should make sure that the primary key is as small as possible, in order to have upscaledb store it in the Btree leaf.
If you do not have a natural primary key, then upscaledb offers a nifty feature called "Record number": It will automagically assign a 32bit (or 64bit) numeric key to each new record, just like MySQL's AUTO_INCREMENT column.
Data Modelling in NoSQL databases
Ultimately, you will often end up with a "primary index", which contains the data for your rows (similar to a "row oriented" storage), and secondary indexes for querying other attributes (as known from the "column oriented" storage). A graphical representation looks like this:
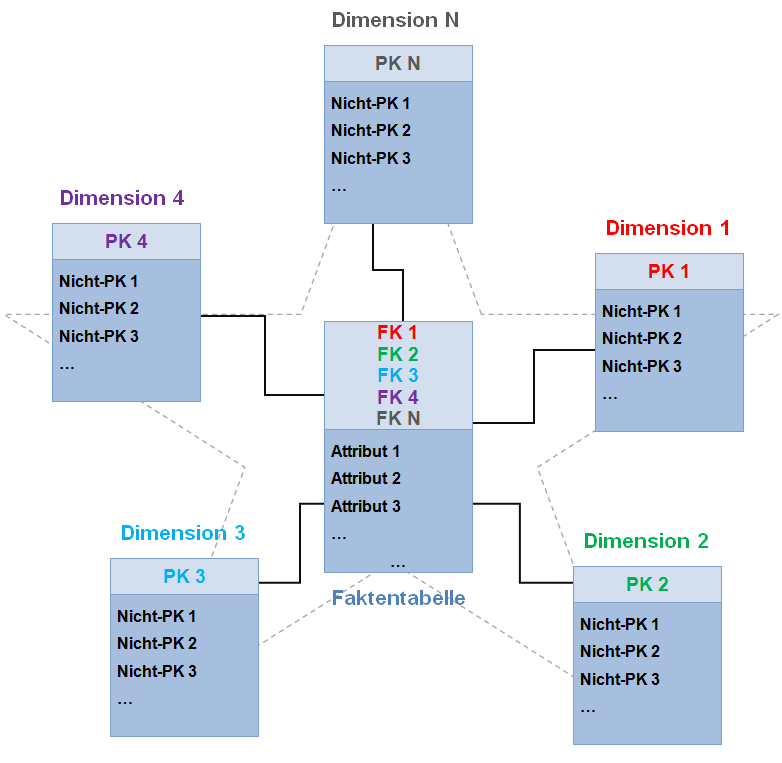
(C) wikipedia, CC BY-SA 3.0
Looks like a star, right? That's why this schema is called "Star Schema". It's a simple way to model your data, especially if the database lacks functionality for more sophisticated models (i.e. enforcing integrity). NoSQL databases work well with the star schema, and upscaledb is no exception. The web has a lot of information about the star schema.
Next time I will show how to implement an improved user database from part 1 with upscaledb, including indexes and range queries.
Latest Posts
Release of upscaledb 2.2.1
Sep 25, 21:23:03 CET 2016
First release of upscaledb-mysql 0.0.1
May 20, 18:55:21 CET 2016
32bit integer compression algorithms - part 3
Apr 11, 19:12:27 CET 2016
32bit integer compression algorithms - part 2
Mar 22, 18:38:21 CET 2016
Fast range queries in upscaledb
Apr 03, 22:26:51 CET 2016
Release of upscaledb 2.2.0