32bit integer compression algorithms - part 2 by Christoph Rupp
Posted on Apr 11, 19:12:27 CET 2016
This blog post continues with the summary of a research paper by Daniel Lemire and me about the use of 32bit integer compression for keys in a B+-tree index. We evaluate a wide range of compression schemes, some of which leverage the SIMD instructions available in modern processors. To our knowledge, such a comparison has never been attempted before.
You can read part one here. This part describes the integration of integer compression in upscaledb and presents benchmark results.
The upscaledb B+-tree
upscaledb’s B+-tree node stores keys and values separately from each other. Each node has a header structure of 32 bytes containing flags, a key counter, pointers to the left and right siblings and to the child node. This header is followed by the KeyList (where we store the key data) and the RecordList (where we store the value’s data). Their layout depends on the index configuration and data types.
The RecordList of an internal node stores 64-bit pointers to child nodes, whereas the RecordList of a leaf node stores values or 64-bit pointers to external blobs if the values are too large.
Fixed-length keys are always stored sequentially and without overhead. They are implemented as plain C arrays of the key type, i.e., uint32 t keys[] for a database of 32-bit integers. Variable-length keys use a small in-node index to manage the keys. Long keys are stored in separate blobs; the B+-tree node then points to this blob.
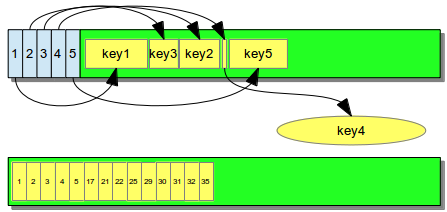
Memory layout for variable-length (top) and fixed-length keys (bottom)
This in-memory representation of fixed-length keys makes applying compression easy - at least in theory. The keys are already stored in sorted order, therefore applying differential encoding does not require a change in the memory layout. Since keys are stored sequentially in memory, SIMD instructions can be used efficiently if needed.
When using integer compression, the keys are split into blocks of up to 256 integers per block. We chose this to offer faster random access (by skipping blocks). Also, inserting or deleting values will only affect a small block instead of a huge one.
Codec requirements
I already described the various codecs in the previous part. In order to integrate a codec into upscaledb, it had to implement a few functions.
uncompress block
A full block is not decoded during CRUD (Create/Read/Update/Delete) operations, but it is decoded frequently during analytical queries (see below).
compress block
Used i.e. after a page split or in the "vacuumize" operation, which periodically compacts a node in order to save space (see below).
insert
Inserts a new integer value in a compressed block. A few codecs (Varbyte, MaskedVByte and VarIntGB) can do this without uncompressing the block. All other codecs uncompress the block, modify it and then re-compress the block.
append
Appending an index key at the “end” of the database is a very common operation, therefore we optimized it. Most codecs are now able to append extremely fast with O(1), and without decoding the whole block. Appending an integer key to a compressed block would otherwise be costly, because all codecs (except FOR and SIMD FOR) have to reconstruct all values because of the differential encoding.
search
Performs a lower-bound search in a compressed block, without decompressing it.
delete
Not a priority since we did not use this in our benchmark. Implemented for Varbyte (and therefore also for MaskedVByte) directly on the compressed data. All other codecs decode the block, delete the value and then re-encode the block again.
vacuumize
Performs a compaction by removing gaps between blocks. Gaps occur when keys are deleted and blocks therefore shrink, or blocks require more space and are moved to a different location in the node. SIMD FOR and BP128 periodically also decode all keys and re-encode them again.
(select)
Was originally used for cursor operations. But then we found out that cursors often access the same block. We decided to decode and cache the last used block. The select function is therefore no longer used.
Benchmarks
All our experiments are executed on an Intel Core i7-4770 CPU (Haswell) with 32 GB memory (DDR3-1600 with double-channel). The CPU has 4 cores of 3.40 GHz each, and 8 MB of L3 cache. Turbo Boost is disabled on the test machine, and the processor is set to run at its highest clock speed. The computer runs Linux Ubuntu 14.04. We report wall-clock time.
Insert
This benchmark creates a new database for 32bit integer keys and inserts various numbers of keys. We should expect a compressed database to be slower for such applications, as insertions may require complete recompression of some blocks, at least in the worst case. Among the compressed formats, the best insertion performance is offered by the FOR, SIMD FOR and Masked VByte codecs, followed by BP128 and VarIntGB. VByte is slower than all other codecs. If one uses FOR, SIMD FOR and Masked VByte, insertions in a compressed database are only 2.5× slower than insertions in an uncompressed database.
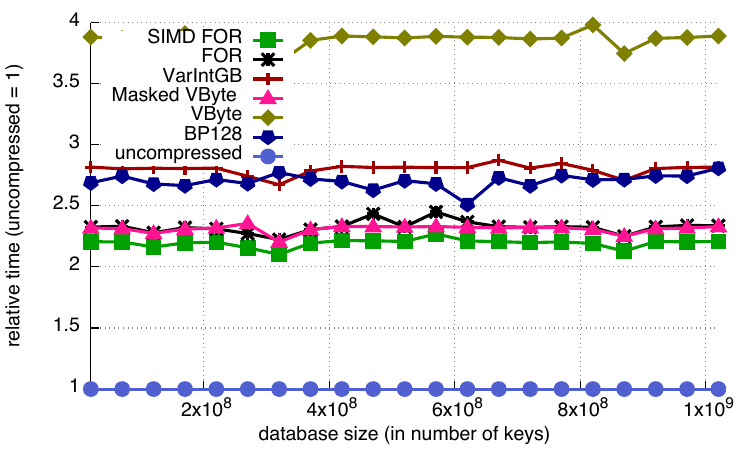
Relative insert timings
Look-ups
This benchmark opens an existing database and performs point look-ups of all inserted keys. Each look-up requires a B+-tree traversal to the leaf node. The node then performs a linear search through the block index and locates the block which stores the requested key. The codec then searches the block for the key.
The benchmarks show that integer compression does not cause a significant performance hit for lookup operations. We get the best results with SIMD FOR, VarIntGB and FOR, and the worst results with VByte and BP128 (with a penalty of up to 60 %). Actually this was a positive surprise; we expected worse!
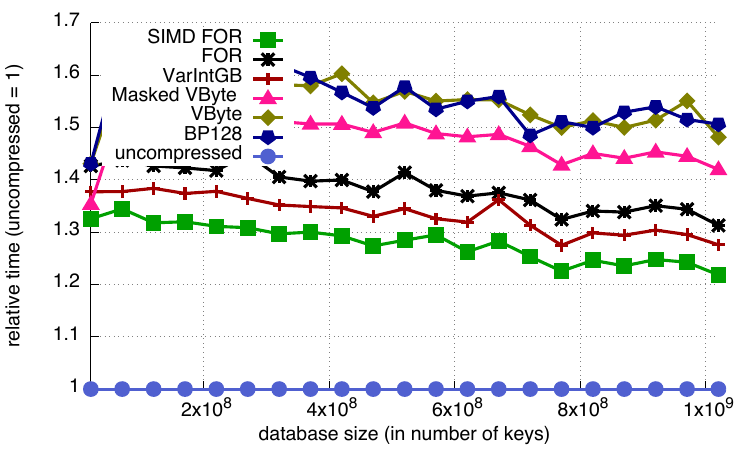
Relative look-up timings
Cursors
This benchmark opens an existing database and creates a cursor to traverse from the first to the last key. To position itself on the first key, the cursor traverses down the B+-tree at the left-most path down to the leaf, then visits each leaf. Since all leaf nodes are linked, no further traversal is required.
In our original implementation, the cursor then used the select method to retrieve the key directly from the compressed block. But since cursors are usually used for sequential access, and therefore frequently access the same block, we decided to decode the block and cache the decoded values. Our tests showed a significant performance improvement compared to the previous implementation based on select.
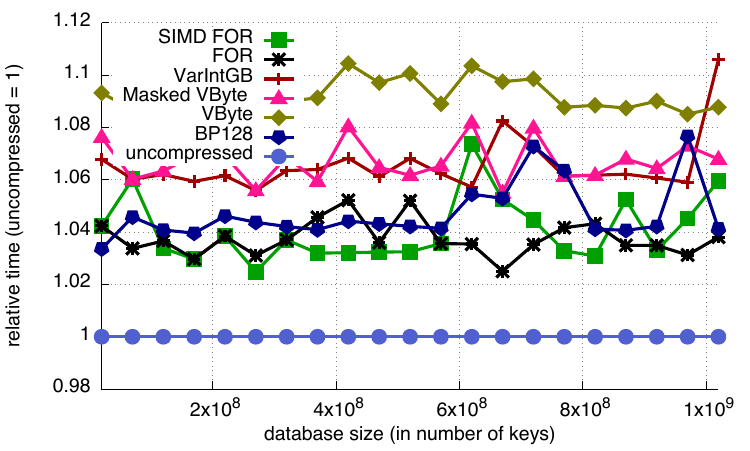
Relative cursor timings
Sum
This benchmark performs a “SUM” operation on all keys. It is equivalent to a SELECT SUM(column) operation of a SQL database, where the specified column is an index of unique 32bit integer keys. For such operations, upscaledb does not use a cursor to traverse the B+-tree, but performs the operation directly on the B+-tree’s data, without copying the keys into the application’s memory. SUM performance is impacted by database size: the bigger the database, the more compression is beneficial, with BP128 and SIMD FOR offering the best performance.
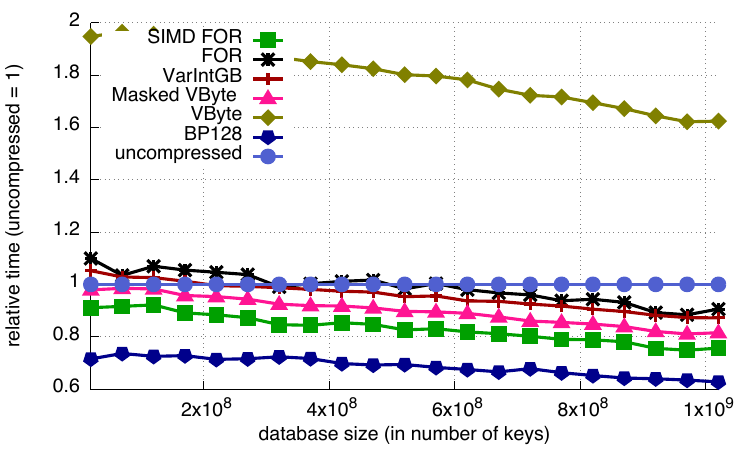
Relative SUM timings
File sizes
Finally, here are the compression results with the various database sizes, using the default block sizes (128 for BP128 and 256 for other codecs). BP128 is the clear winner. It is able to compress the database by a factor of ten compared to an uncompressed B+-tree. The compression ratios offered by the other codecs are similar (compression ratio of 2 or 3), with SIMD FOR compressing slightly less and VByte compressing slightly better.
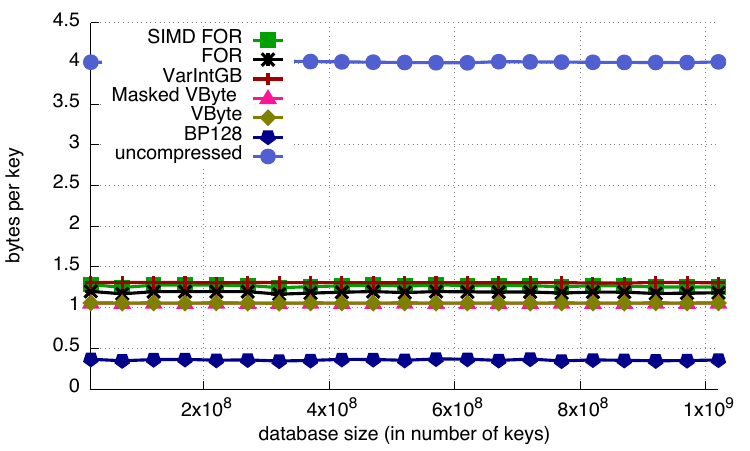
Relative database sizes
Conclusion
We have shown that fast key compression could improve the single-threaded performance of a key-value store - if these compression techniques are accelerated with SIMD instructions. We get the best performance for SIMD codecs (BP128 and SIMD FOR). Unlike other codecs, they show an ability to noticeably improve query performance in all our tests (from small to large databases) on the analytic “SUM” benchmark.
Another conclusion would be: if your application mostly appends keys (instead of inserting them at random positions), and you perform many analytical queries or full-table scans, then performance will improve (in the best case) or at least not deteriorate significantly (in the worst case). But you will save lots of RAM.
One of our codecs, BP128 ("SimdComp"), comes with an interesting limitation: it is not "delete stable" and often grows when keys are deleted. To our knowledge, upscaledb is the only database which is able to deal with such codecs. In the next blog I'll describe how we did this, a few other problems we faced when we integrated compression, and how upscaledb's B+-tree differs from the textbook B-tree algorithm. Sign up to our newsletter to get notified when the next blog is published.
Follow me on Twitter!
Latest Posts
32bit integer compression algorithms - part 3
Apr 11, 19:12:27 CET 2016
32bit integer compression algorithms - part 2
Mar 22, 18:38:21 CET 2016
Fast range queries in upscaledb
Apr 03, 22:26:51 CET 2016
Release of upscaledb 2.2.0
Mar 08, 21:02:54 CET 2016
32bit integer compression algorithms
Feb 10, 20:12:32 CET 2016
Building an embedded column store database with upscaledb - part 3